To analyze the structure of the FP networks, we decompose each network into communities. A community is a set of nodes that are strongly interconnected in comparison to the connections to nodes outside the community. This general idea of community is made precise in terms of the modularity of Girvan and Newman (2004), with some relatively minor adaptations (Barber, 2007) to take into account the bipartite nature of the FP networks.
Community identification is then a search for high modularity partitions of the vertices into disjoint sets. An exhaustive search for the globally optimal solution is only feasible for the smallest networks, as the number of possible partitions of the vertices grows far too rapidly with network size. Several heuristics exist to find high-quality, if suboptimal, solutions in a reasonable length of time. For the FP networks, we use a two-stage search procedure:
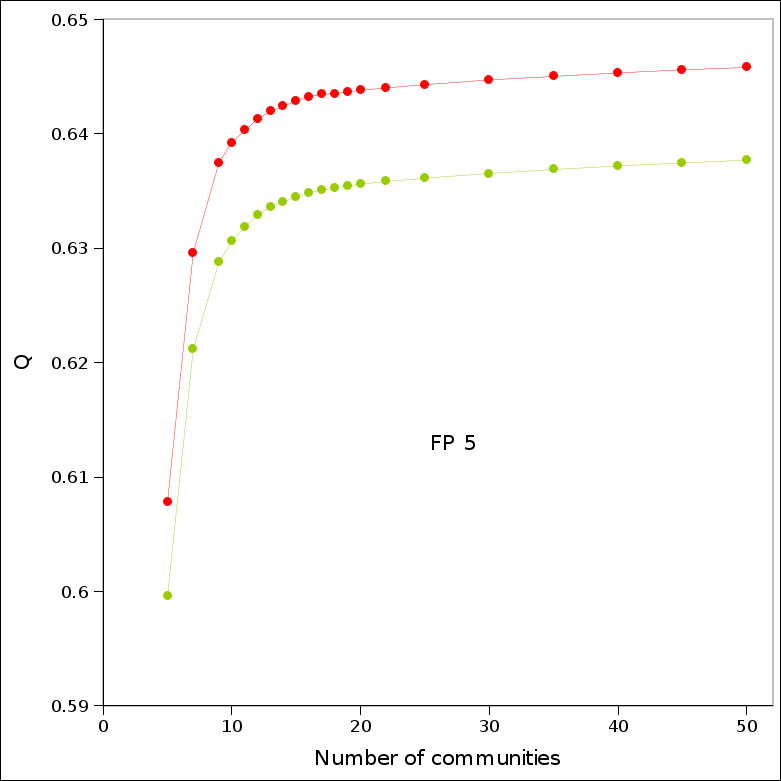
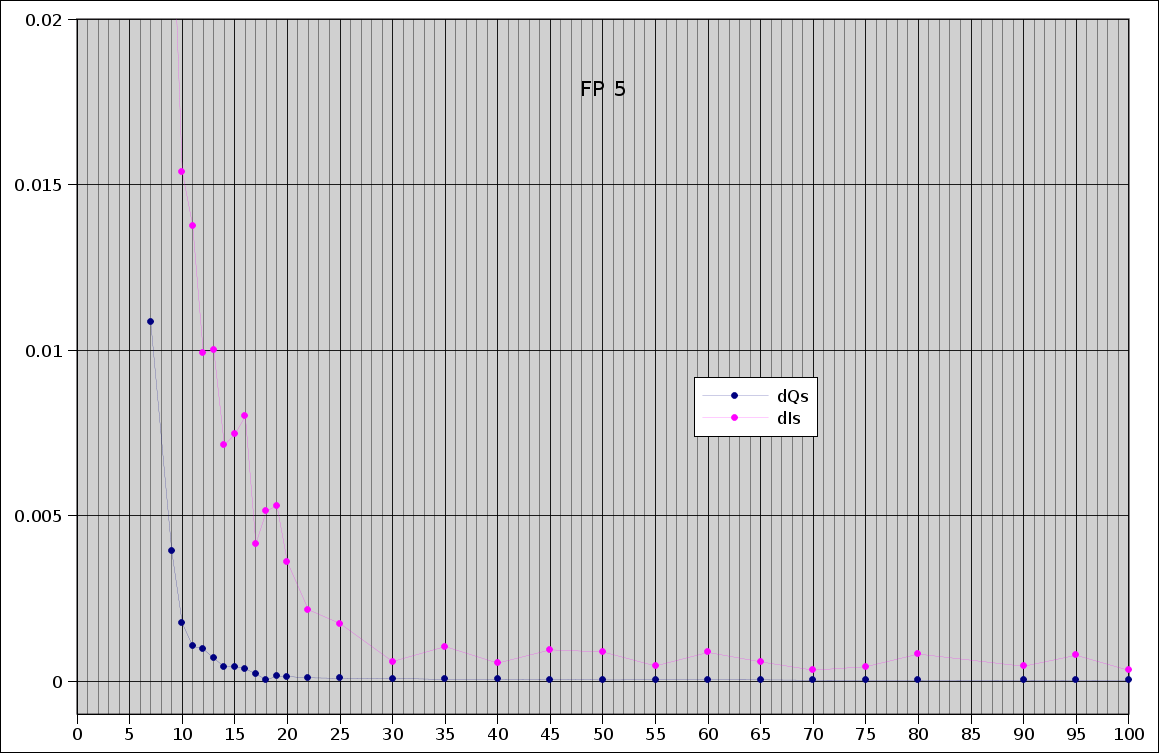
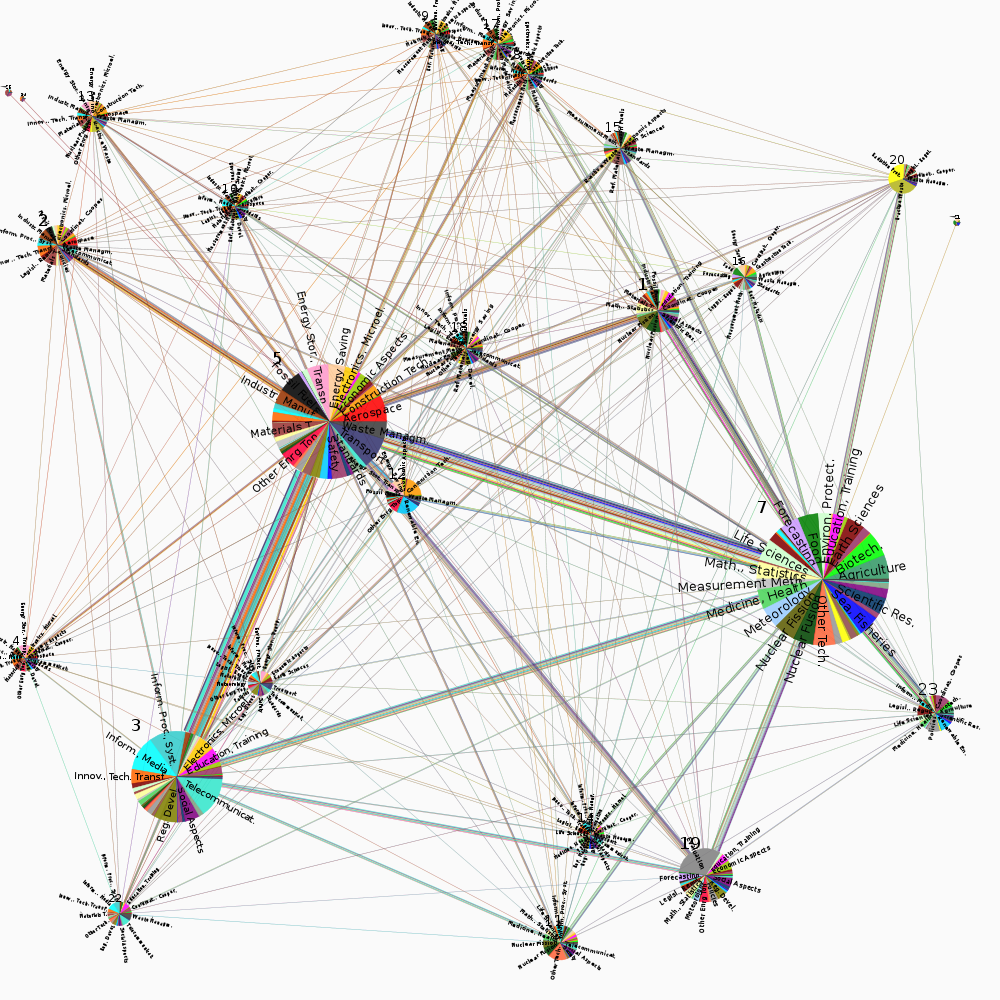
We identified communities for the FP networks using the above approach. For visualization purposes, we take a solution with fewer communities than the best found, but still with high modularity and strong similarity to the best solution, as measured by normalized mutual information (Danon et al, 2005). FP5 is typical, with the modularity within 90% of the best found and mutual information of over 0.8. The number of communities is chosen as small as possible, but still on the broad plateau of similar quality solutions; the solution is easily found by examining the rate of change of the modularity and mutual information.
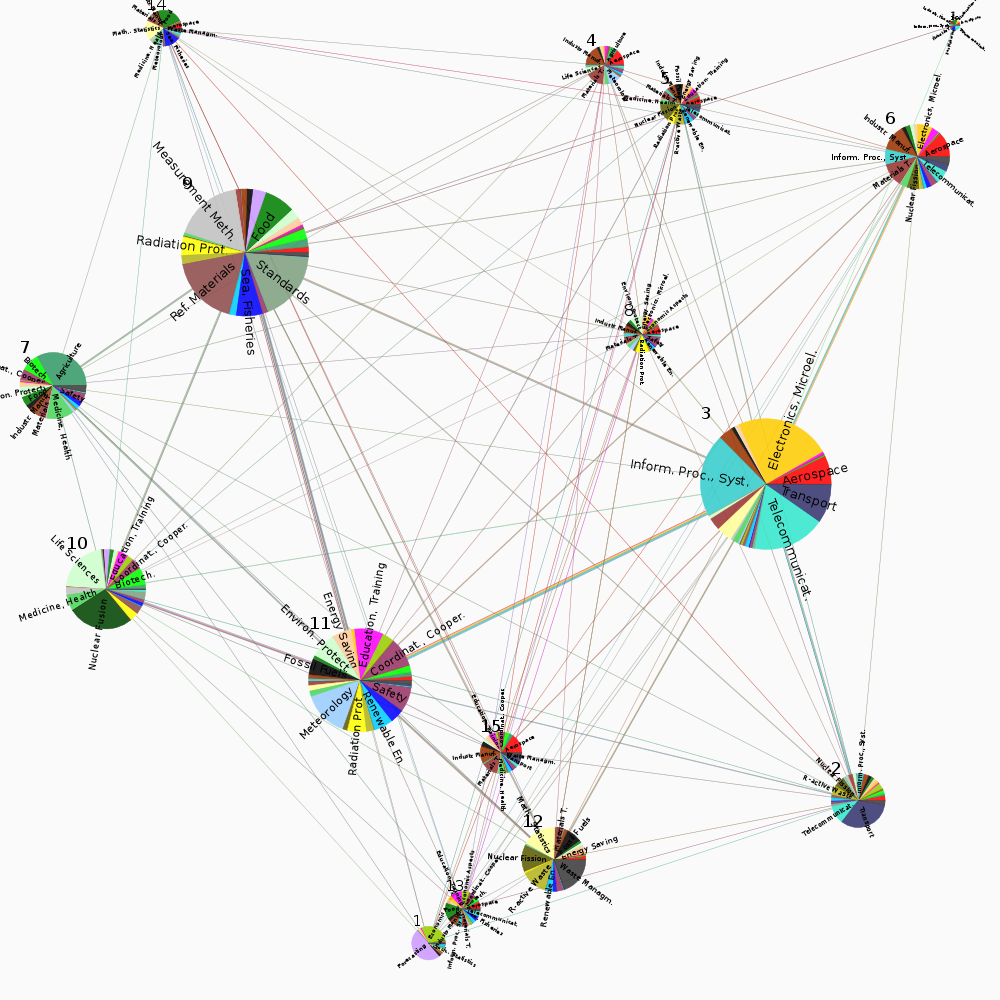
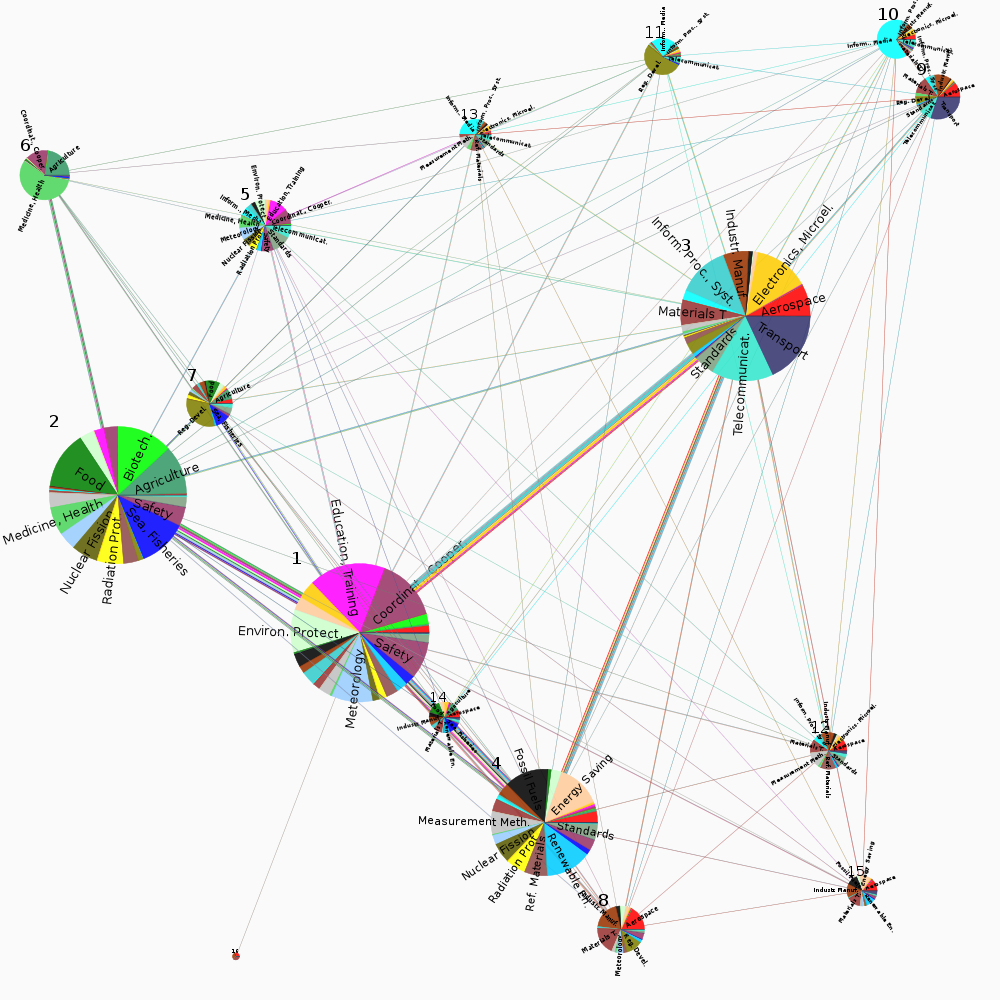
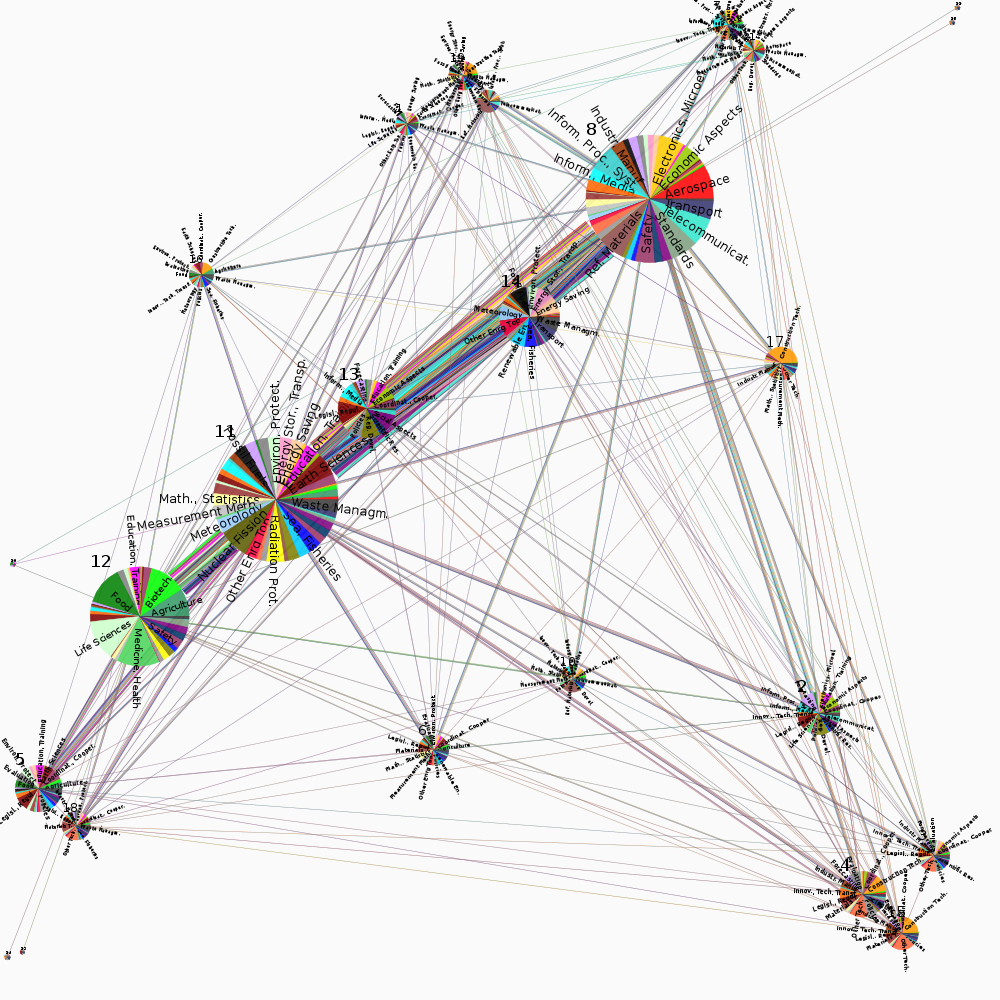
The solutions are visualized with Netzcope, using colors to show project subject indices within and between communities:
As seen in the figures, the community solutions found show topical grouping of projects, based on the project subject indices. This is not surprising, as research areas are expected to have an influence on collaborative intensity.The communities are differentiated from one another—and the network as a whole—not only by topical properties of the projects, but also by properties of the organizations in the communities. For example, communities 15 and 20 from FP5 show markedly different patterns for the countries where the organizations are located. The type of organization also plays a role, as can be seen from communities 1 and 2 from FP5.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}